Pertanyaan ini muncul dari kebingungan aktual saya tentang bagaimana memutuskan apakah model logistik cukup baik. Saya memiliki model yang menggunakan keadaan berpasangan-proyek individu dua tahun setelah mereka dibentuk sebagai variabel dependen. Hasilnya berhasil (1) atau tidak (0). Saya memiliki variabel independen yang diukur pada saat pembentukan pasangan. Tujuan saya adalah untuk menguji apakah suatu variabel, yang saya hipotesiskan akan mempengaruhi keberhasilan pasangan memiliki pengaruh pada keberhasilan itu, mengendalikan pengaruh potensial lainnya. Dalam model, variabel yang menarik adalah signifikan.
Model diperkirakan menggunakan glm()fungsi dalam R. Untuk menilai kualitas model, saya telah melakukan beberapa hal: glm()memberi Anda residual deviance, AICdan BICsecara default. Selain itu, saya telah menghitung tingkat kesalahan model dan merencanakan residu binned.
- Model lengkap memiliki penyimpangan residual yang lebih kecil, AIC dan BIC daripada model lain yang saya perkirakan (dan yang bersarang dalam model lengkap), yang membuat saya berpikir bahwa model ini "lebih baik" daripada yang lain.
- Tingkat kesalahan model cukup rendah, IMHO (seperti dalam Gelman dan Hill, 2007, hal.99 ) :,
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)sekitar 20%.
Sejauh ini baik. Tetapi ketika saya memplot sisa binned (sekali lagi mengikuti saran Gelman dan Hill), sebagian besar nampan berada di luar 95% CI:
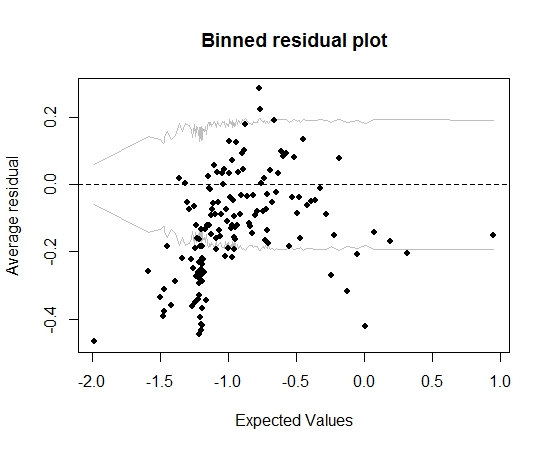
Plot itu membuat saya berpikir ada sesuatu yang salah dengan model itu. Haruskah itu membuat saya membuang model itu? Haruskah saya mengakui bahwa model itu tidak sempurna tetapi menyimpannya dan menafsirkan efek dari variabel yang diminati? Saya telah bermain-main dengan mengecualikan variabel pada gilirannya, dan juga beberapa transformasi, tanpa benar-benar meningkatkan plot residual binned.
Edit:
- Saat ini, model memiliki selusin prediktor dan 5 efek interaksi.
- Pasangan "relatif" independen satu sama lain dalam arti bahwa mereka semua terbentuk selama periode waktu yang singkat (tetapi tidak secara tegas, semuanya secara bersamaan) dan ada banyak proyek (13 k) dan banyak individu (19 k ), sehingga sebagian besar proyek hanya diikuti oleh satu orang (ada sekitar 20.000 pasangan).
sumber
Jawaban:
Akurasi klasifikasi (tingkat kesalahan) adalah aturan penilaian yang tidak tepat (dioptimalkan oleh model palsu), sewenang-wenang, terputus-putus, dan mudah dimanipulasi. Ini tidak diperlukan dalam konteks ini.
Anda tidak menyebutkan berapa banyak prediktor yang ada. Alih-alih menilai model yang cocok saya akan tergoda untuk hanya membuat model yang cocok. Pendekatan kompromi adalah mengasumsikan bahwa interaksi tidak penting dan untuk memungkinkan prediktor kontinu menjadi nonlinear menggunakan splines regresi. Plot hubungan yang diperkirakan. The
rmspaket di R membuat semua ini relatif mudah. Lihat http://biostat.mc.vanderbilt.edu/rms untuk informasi lebih lanjut.Anda mungkin menguraikan "pasangan" dan apakah pengamatan Anda independen.
sumber
sumber