Saya baru-baru melakukan pekerjaan rumah di mana saya harus belajar model untuk klasifikasi 10 digit MNIST. HW memiliki beberapa kode perancah dan saya seharusnya bekerja dalam konteks kode ini.
Pekerjaan rumah saya bekerja / lulus tes tetapi sekarang saya mencoba untuk melakukan semuanya dari awal (kerangka kerja saya sendiri, tidak ada kode perancah hw) dan saya terjebak menerapkan grandient dari softmax pada langkah backprop, dan bahkan berpikir apa hw kode scaffolding mungkin tidak benar.
Hw meminta saya menggunakan apa yang mereka sebut 'kerugian softmax' sebagai simpul terakhir di nn. Yang berarti, untuk beberapa alasan mereka memutuskan untuk bergabung dengan aktivasi softmax dengan cross entropy loss secara keseluruhan, alih-alih memperlakukan softmax sebagai fungsi aktivasi dan cross entropy sebagai fungsi loss terpisah.
Fungsi hw loss kemudian terlihat seperti ini (minimal diedit oleh saya):
class SoftmaxLoss:
"""
A batched softmax loss, used for classification problems.
input[0] (the prediction) = np.array of dims batch_size x 10
input[1] (the truth) = np.array of dims batch_size x 10
"""
@staticmethod
def softmax(input):
exp = np.exp(input - np.max(input, axis=1, keepdims=True))
return exp / np.sum(exp, axis=1, keepdims=True)
@staticmethod
def forward(inputs):
softmax = SoftmaxLoss.softmax(inputs[0])
labels = inputs[1]
return np.mean(-np.sum(labels * np.log(softmax), axis=1))
@staticmethod
def backward(inputs, gradient):
softmax = SoftmaxLoss.softmax(inputs[0])
return [
gradient * (softmax - inputs[1]) / inputs[0].shape[0],
gradient * (-np.log(softmax)) / inputs[0].shape[0]
]
Seperti yang Anda lihat, pada maju tidak softmax (x) dan kemudian lintas kehilangan entropi.
Tetapi pada backprop, tampaknya hanya melakukan turunan dari cross entropy dan bukan dari softmax. Softmax dibiarkan seperti itu.
Bukankah seharusnya juga mengambil turunan dari softmax sehubungan dengan input ke softmax?
Dengan asumsi bahwa itu harus mengambil turunan dari softmax, saya tidak yakin bagaimana hw ini benar-benar lulus tes ...
Sekarang, dalam implementasi saya sendiri dari awal, saya membuat softmax dan cross entropy node yang terpisah, seperti itu (p dan t berarti prediksi dan kebenaran):
class SoftMax(NetNode):
def __init__(self, x):
ex = np.exp(x.data - np.max(x.data, axis=1, keepdims=True))
super().__init__(ex / np.sum(ex, axis=1, keepdims=True), x)
def _back(self, x):
g = self.data * (np.eye(self.data.shape[0]) - self.data)
x.g += self.g * g
super()._back()
class LCE(NetNode):
def __init__(self, p, t):
super().__init__(
np.mean(-np.sum(t.data * np.log(p.data), axis=1)),
p, t
)
def _back(self, p, t):
p.g += self.g * (p.data - t.data) / t.data.shape[0]
t.g += self.g * -np.log(p.data) / t.data.shape[0]
super()._back()
Seperti yang Anda lihat, cross entropy loss (LCE) saya memiliki turunan yang sama dengan yang ada di hw, karena itu adalah turunan dari kerugian itu sendiri, tanpa masuk ke softmax.
Tapi kemudian, saya masih harus melakukan turunan softmax untuk rantai itu dengan turunan dari kerugian. Di sinilah saya terjebak.
Untuk softmax didefinisikan sebagai:
Derivatif biasanya didefinisikan sebagai:
Tapi saya butuh turunan yang menghasilkan tensor dengan ukuran yang sama dengan input ke softmax, dalam hal ini, batch_size x 10. Jadi saya tidak yakin bagaimana yang di atas harus diterapkan pada hanya 10 komponen, karena ini menyiratkan bahwa saya akan membedakan semua input sehubungan dengan semua output (semua kombinasi) atau dalam bentuk matriks.
sumber
Jawaban:
Setelah lebih lanjut mengerjakan ini, saya menemukan bahwa:
Implementasi pekerjaan rumah menggabungkan softmax dengan cross entropy loss sebagai pilihan, sementara pilihan saya untuk menjaga softmax terpisah sebagai fungsi aktivasi juga valid.
Implementasi pekerjaan rumah memang kehilangan turunan softmax untuk pass backprop.
Gradien dari softmax sehubungan dengan inputnya adalah benar-benar bagian dari setiap output sehubungan dengan setiap input:
Jadi untuk bentuk vektor (gradien):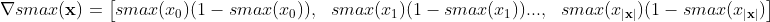
Yang dalam kode numpy vektorized saya hanya:
Di mana
self.datasoftmax input, yang sebelumnya dihitung dari umpan maju.sumber